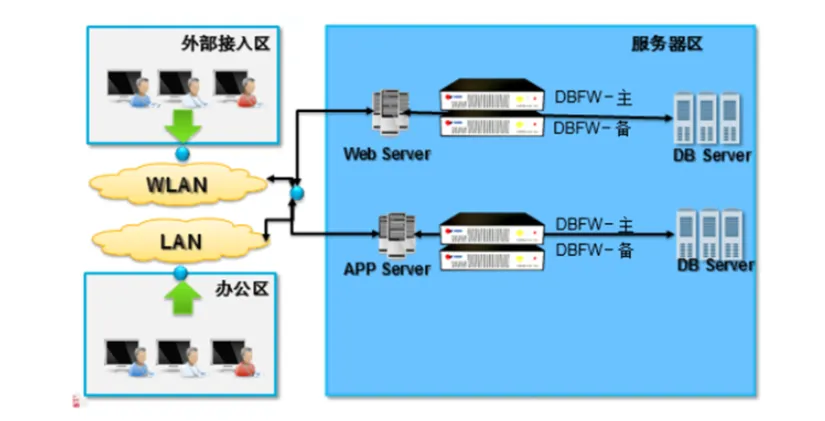
一、什么是HW
网络安全形势近年出现新变化,网络安全态势变得越来越复杂,黑客攻击入侵、勒索病毒等网络安全事件愈演愈烈,严重威胁到我国的网络空间安全。同时,国内不少关键信息基础设施的建设管理单位安全意识不够、安全投入不足,面临网络安全保护的巨大挑战,让国家关键信息基础设施成为网络攻击的重灾区。
护网行动是由公安部牵头,针对全国范围的真实网络目标单位进行的一种网络安全攻防演练。这种行动的主要目的是评估企事业单位的网络安全防护能力和水平,发现可能存在的安全漏洞,并提升相关人员的网络安全意识和应对能力。
在护网行动中,公安部会组织攻防两方,其中进攻方会在特定的时间内对防守方发动网络攻击,通过模拟真实的网络威胁来检验防守方的网络安全防护措施是否有效。这种实战化的演练有助于企事业单位更好地了解自身的网络安全状况,从而有针对性地加强防护措施。
护网行动是一种积极、有效的网络安全防护措施,它通过实战化的演练来提升网络安全防护能力,确保网络系统的安全和稳定。
二、HW行动具体采取了哪些攻防演练措施
护网行动采取了多种攻防演练措施,以模拟和应对网络攻击,从而提升网络安全防护能力。以下是一些具体的攻防演练措施:
- 制定演练计划:明确演练的目标、参与人员、时间和场地,为演练准备必要的设备、工具和系统环境。
- 设定演练情景:设定模拟黑客攻击、内部威胁、网络故障等演练情景,这些情景通常包括不同类型的攻击技术和威胁,以全面检验网络系统的防御能力。
- 实施攻防演练:根据设定的情景,模拟攻击者进行攻击,挑战网络安全防御能力。同时,团队成员需要响应并采取相应的应对措施,以检验和锻炼他们的响应和处置能力。
- 攻击分析和演练评估:记录并分析攻击过程,对攻击行为进行深入剖析。同时,评估团队的反应和应对能力,发现并修复存在的漏洞和弱点。
- 总结和改进:总结演练结果,包括表现出色的方面和需要改进的方面,并制定改进措施和行动计划,以加强网络安全防御。
这些措施旨在通过实战模拟,全面检验和提升网络系统的安全防护能力,确保在面对真实网络攻击时能够迅速、有效地进行应对。同时,护网行动还促进了网络安全团队的协作和沟通,提升了整体的安全意识和应对能力。
需要注意的是,攻防演练过程中需要确保参与者的安全和免受损害,避免演练本身对网络系统造成不必要的风险。因此,在演练过程中需要严格遵守安全规定和操作流程,确保演练的顺利进行和目标的达成。
三、攻击方一般的攻击流程和方法
HW攻防演练的安全评价关注点已经从安全防护投入过渡到讲究实战效果,拒绝纸上谈兵,直接真枪实战。
攻击方一般目标明确、步骤清晰。
目标明确: 攻击者只攻击得分项,和必要路径(外网入口,内网立足点),对这些目标采取高等级手段,会隐蔽操作;对非必要路径顺路控制下来的服务器,并不怕被发现,用起来比较随意,甚至主动制造噪音,干扰防守方。
步骤清晰: 信息收集-控制入口-横向移动-维持权限-攻击目标系统。
攻击流程: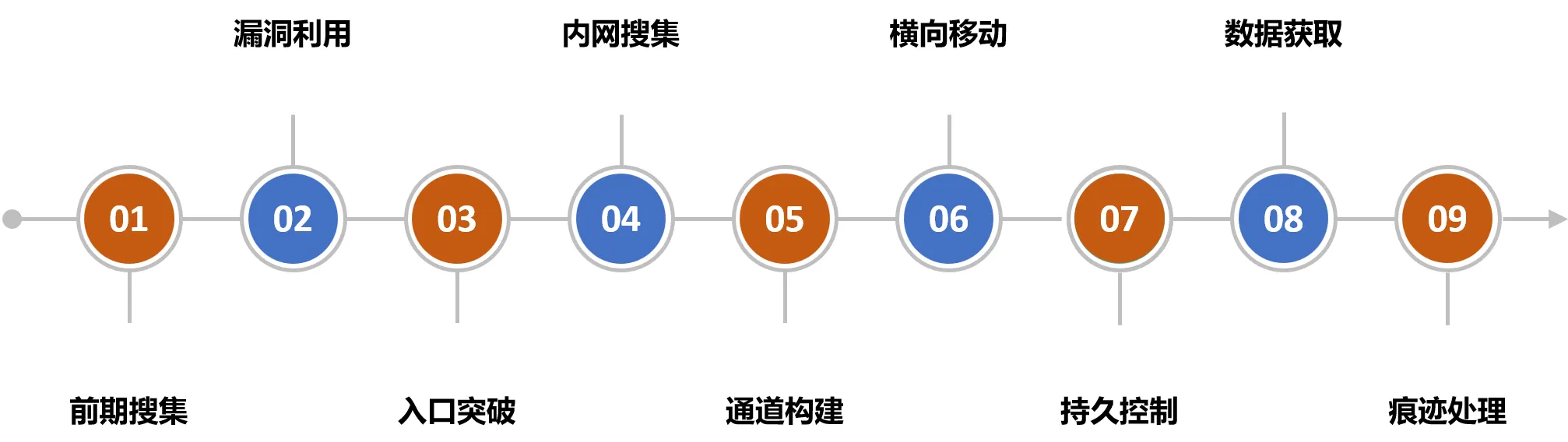
攻击手法: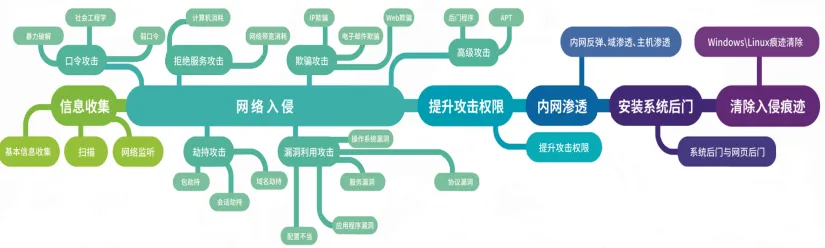
四、企业HW保障方案
企业护网安全保障是一个多层次、多方面的综合性任务,涉及技术、管理、人员培训等多个环节。以下是一些关键措施,可以帮助企业加强护网安全保障: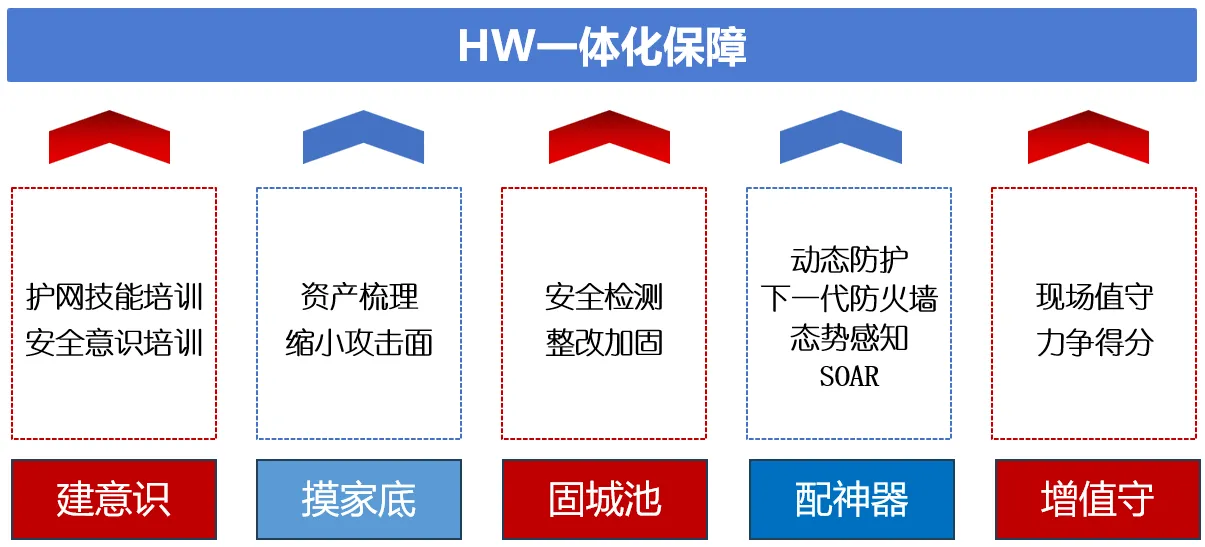
1.建意识
护网安全意识培训是一项至关重要的工作,它旨在提升个人和组织对网络安全的认识和应对能力,从而保护个人隐私、企业数据以及整个网络环境的安全。
首先,培训应涵盖网络安全的基本概念、原则和特点,包括密码安全、网络钓鱼、恶意软件等。这有助于人们理解网络安全的重要性,以及如何在日常生活中识别和防范网络威胁。
其次,培训内容应根据不同岗位的需求进行个性化设计。例如,对于IT人员,可以强调网络漏洞扫描和安全配置等专业技能;而对于普通员工,则应重点强调密码安全、社交工程攻击的防范等基础知识。
此外,培训内容还需与最新的网络威胁和漏洞保持同步,确保培训的实用性和时效性。这有助于人们了解最新的网络攻击手法和防范措施,从而更有效地应对网络威胁。
企业需要向员工提供网络安全意识培训,使他们了解各种网络威胁和攻击方式,并知道如何避免和应对这些威胁。包括护网技能的培训,通过模拟黑客攻击等场景,让员工在实际操作中学习和掌握网络安全技能。
2.摸家底
护网资产梳理是缩小攻击面的关键步骤,有助于企业更好地了解自身的网络安全状况,从而制定更有效的安全防护策略。
首先,明确资产梳理的目标和范围。这包括确定需要梳理的资产类型,如硬件资产、软件资产、数据资产等,以及梳理的深度和广度。通过明确目标和范围,可以确保资产梳理工作的针对性和有效性。梳理互联网类业务、暴露面、中间件、业务管理后台、供应链、 WIFI、VPN、安全意识、终端等边界突破点,实施清查和管控,缩小攻击面。
其次,收集资产信息并建立清单。通过收集资产的详细信息,如IP地址、设备名称、操作系统、数据库类型等,可以建立全面的资产清单。这有助于企业对自身的资产进行清晰的了解,并为后续的安全评估和风险分析提供基础数据。
3.固城池
护网行动中的安全检测和整改加固是确保企业网络安全的重要环节。通过安全检测,可以发现潜在的安全隐患和漏洞,而整改加固则是针对这些问题采取具体的措施,以提升网络安全防护能力。
在安全检测方面,可以采取多种手段,如渗透测试、漏洞扫描、代码审查等。渗透测试通过模拟黑客的攻击方式来评估系统的安全性,发现潜在的漏洞和薄弱点。漏洞扫描则是使用自动化工具扫描网络和系统,识别存在的安全漏洞,并提供修补建议。代码审查则是对软件代码进行详细的审核和分析,以发现可能的安全漏洞。
在进行安全检测后,需要根据检测结果制定整改加固方案。整改加固措施可能包括强化设备访问控制、安装防火墙和入侵检测系统、建立虚拟专用网络(VPN)、限制网络服务和端口等。此外,加强用户身份认证也是关键的一环,包括强化密码策略、使用多因素身份认证、建立访问权限管理机制等。
4.配神器
配置相应的有效防护技防手段,“护网神器”通常指的是一系列网络安全产品和解决方案,它们被设计用来保护企业的网络系统免受各种网络攻击的威胁。这些神器能够检测和防御各类网络攻击,包括但不限于病毒、木马、黑客攻击、钓鱼网站等。它们通过采用先进的技术手段如:动态防护、下一代防火墙、态势感知平台、SOAR等。进行实时监控和预警、智能防御和攻击溯源、高效的自动处置等。
实时监控和预警:通过部署流量探针、EDR、态势感知平台等建立监控手段实时监控网络流量和用户行为,一旦检测到异常或可疑活动,立即发出预警,提醒管理员进行处置。
智能防御和攻击溯源:通过部署下一代防火墙、动态防护设备等平台建立智能防御功能,能够自动识别和阻断攻击行为。同时,它还能对攻击进行溯源,帮助管理员定位攻击源头,采取相应的措施进行防范。
高效快速处置:通过部署SOAR,能够针对实时监控发现的安全告警事件,通过实战化的剧本来联动人员、流程、安全设备进行快速的研判和阻断。
5.增值守
在护网行动中,增加监控值守是一项重要的举措,7*24小时监控值守可以帮助企业实时了解网络系统的运行状态和安全状况。通过对网络流量、系统日志、用户行为等进行实时监控,可以及时发现异常和可疑活动,从而迅速采取措施进行处置。
为了增加监控值守的有效性,企业可以采取以下措施:
- 建立专门的监控团队,负责网络系统的实时监控和安全事件的处置。
- 配置先进的监控设备和软件,确保能够全面、准确地收集和分析网络数据。
- 制定完善的监控流程和规范,确保监控工作的有序进行。
- 加强监控人员的培训和教育,提高其专业技能和应对能力。
博客地址:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!