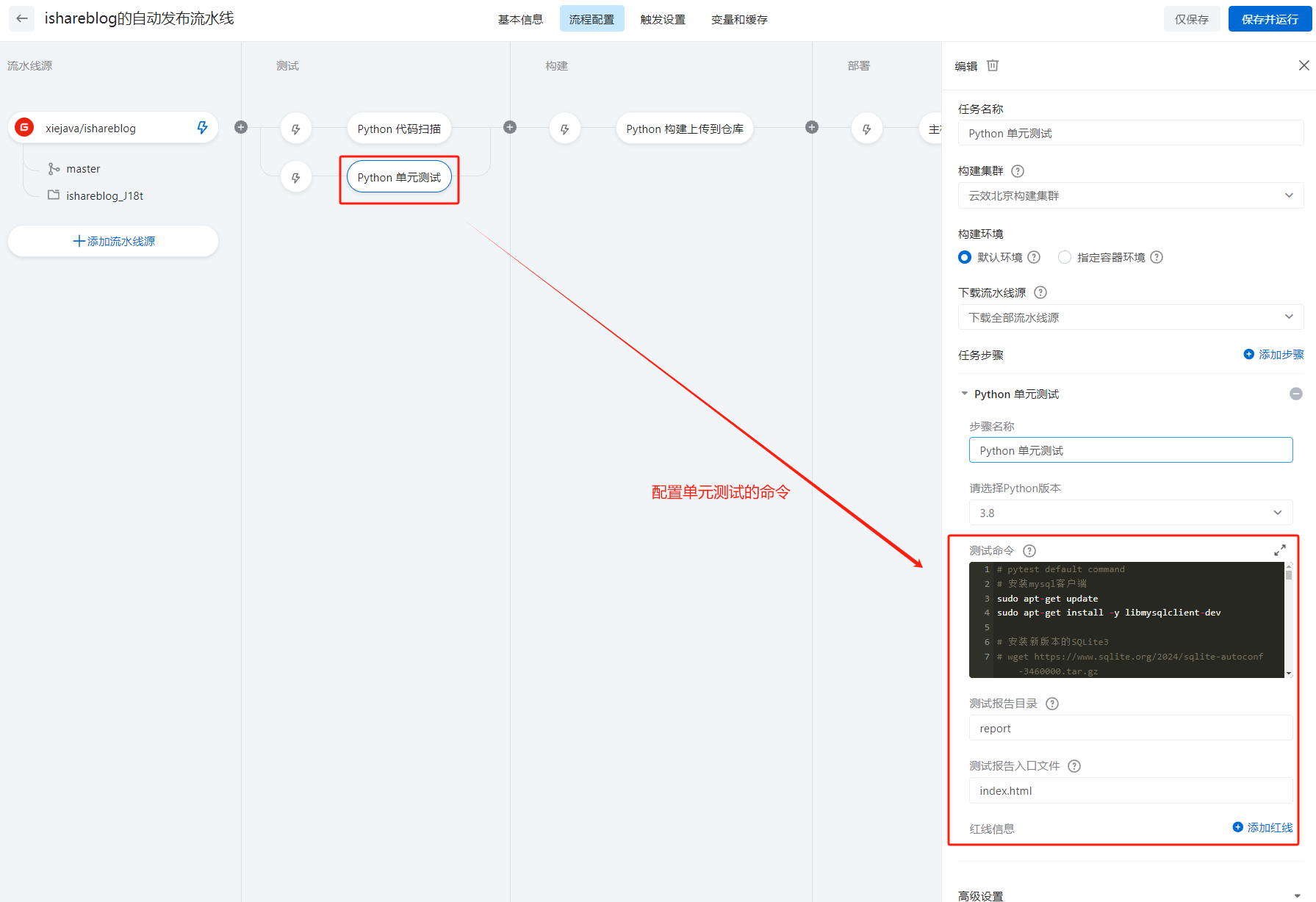
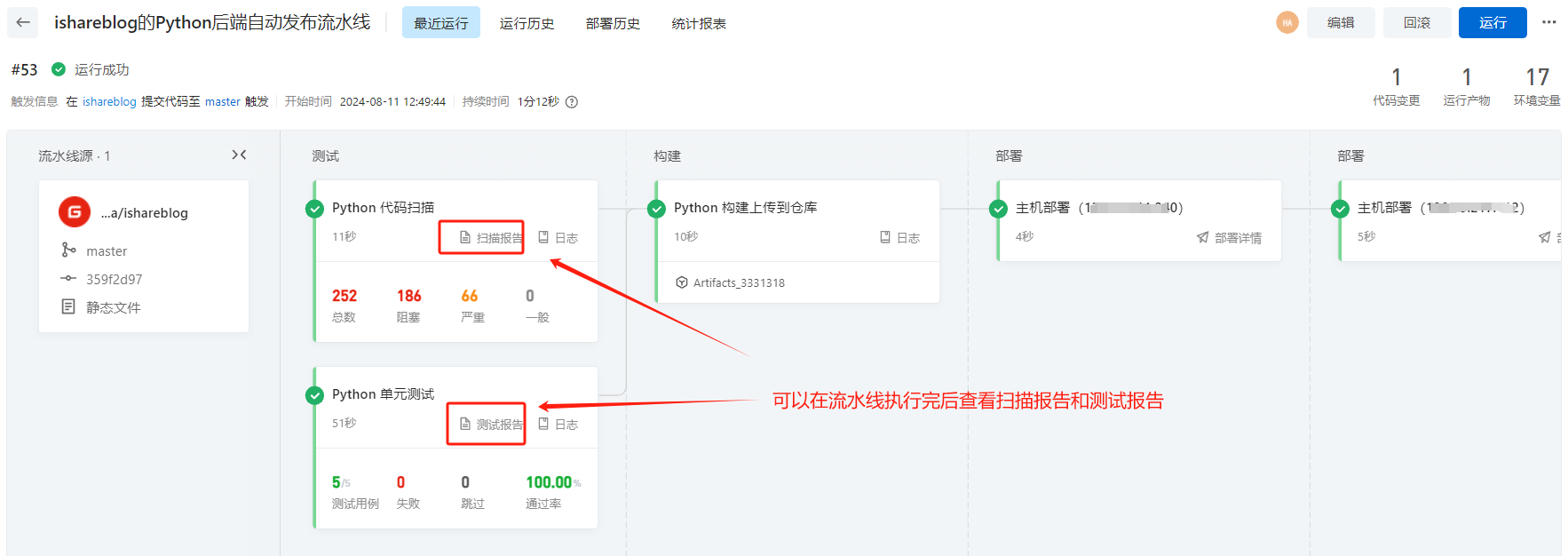
在vue的实际项目中都要经过开发、测试、然后上生产的阶段,在开发、测试的过程中往往会要频繁的切换开发、测试、生产等不同的环境。每个环境的配置有可能不一样,本文介绍如何通过vue3+vite配置环境变量实现开发、测试、生产灵活便捷的切换。
一、为什么需要区分 (dev)、测试 (test) 和生产 (prod) 环境
做过大型项目开发的都知道,每个项目都会要经历开发、测试、再到生产上线,一般在开发时候最常用到(development)开发环境、(production)生产环境、(test)测试环境。每个环境的配置可能都不太一样。
- 开发环境:为开发人员提供一个安全的地方来进行编码和调试,不会影响到其他环境,一般来说开发人员在本地机器上运行和测试应用程序。
- 测试环境:用于测试,模拟生产环境,确保新功能在部署前能够正常工作,并且不会影响现有功能。
- 生产环境:是面向用户的最终环境,任何更改都必须经过严格的测试才能部署到这里,通常具有优化和最少的日志记录。
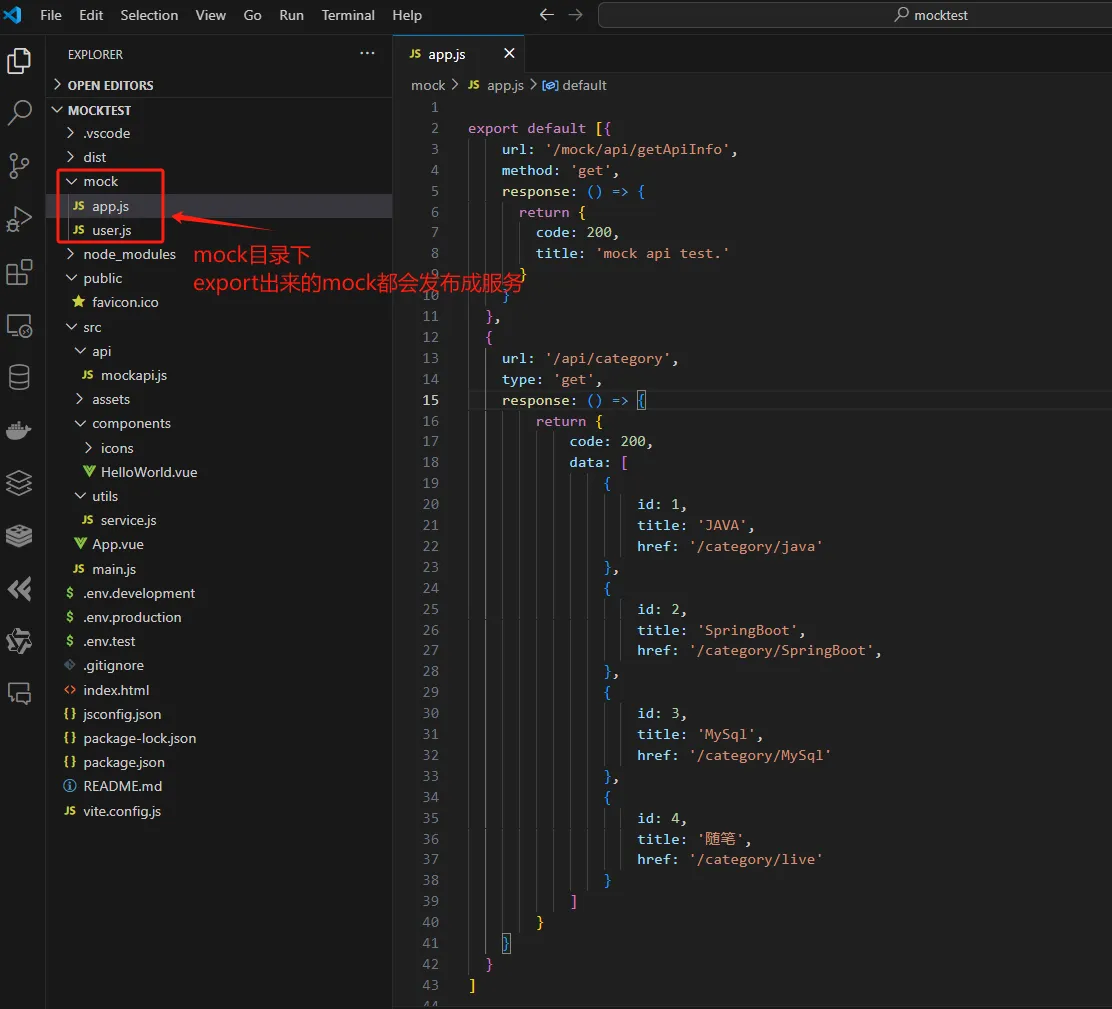
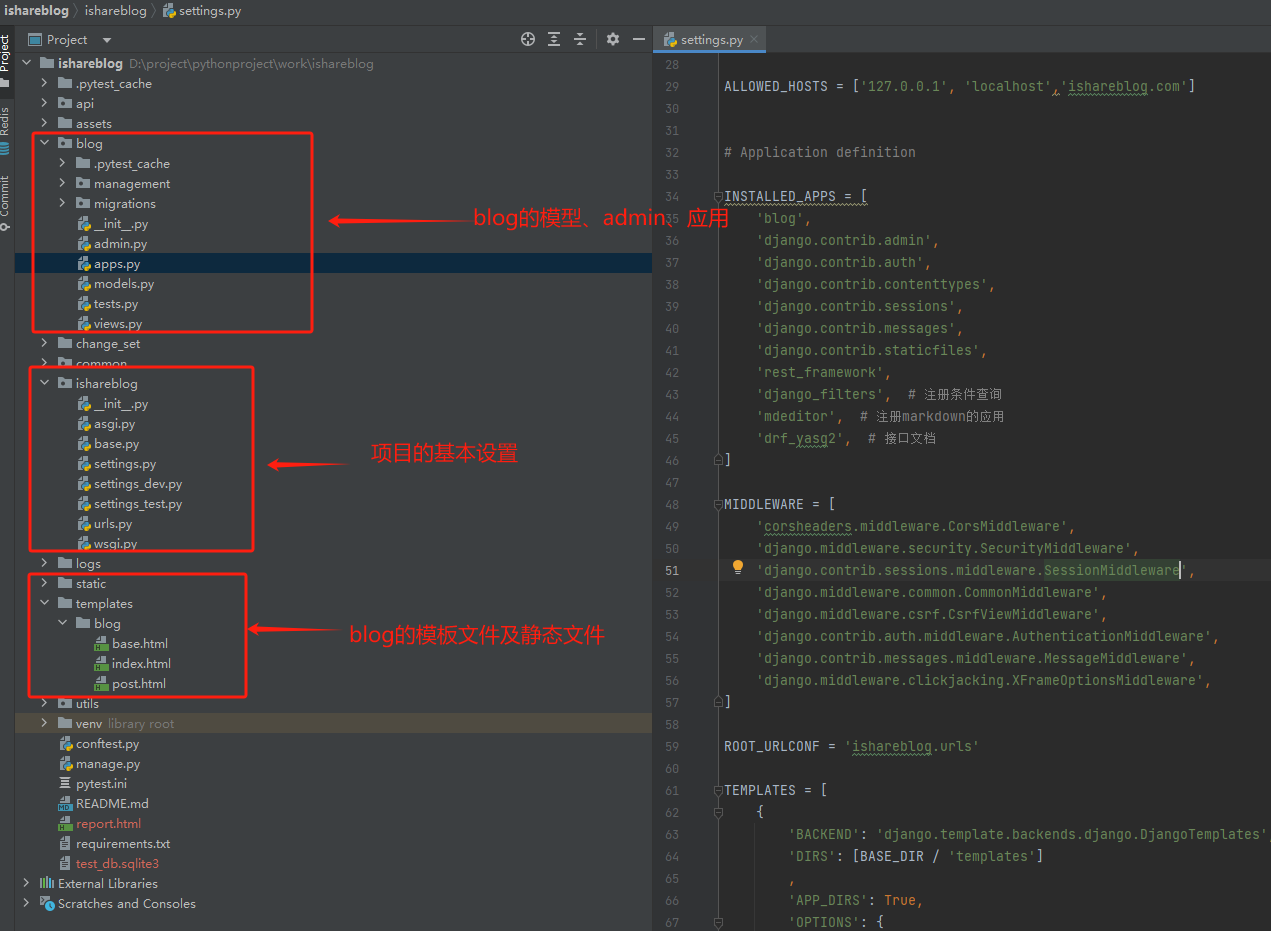
区分开发 (dev)、测试 (test) 和生产 (prod) 环境是软件开发中的一个最佳实践。不同的环境通常有不同的资源配置。典型的如vue所调用的后台接口数据,在开发平台可能是本地服务提供的接口、用于自动化测试可能是mock提供的数据、生产应该是正式环境提供的真实接口。
二、vue3的项目如何通过配置方式区分不同的环境
vue3的项目可以通过vite的环境变量配置来进行不同环境的配置,可以参考vite的官方文档《环境变量和模式》
接下来,我们以一个实例来介绍在vue3的项目如何通过vite配置方式区分不同的环境。
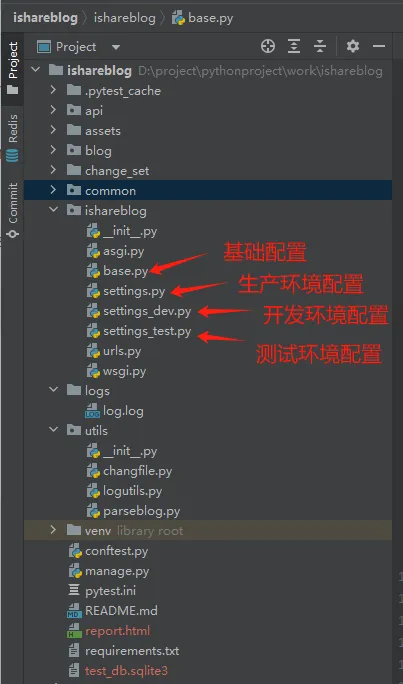
1、创建不同环境的.env文件
在vue3根目录下创建三个文件分别为.env.develoment、.env.test、.env.production
创建的文件需要.env开头

2、在不同的.env文件中配置相应的环境变量
1).env.develoment
1 | NODE_ENV='development' |
2).env.test
1 | NODE_ENV='test' |
3).env.production
1 | NODE_ENV='production' |
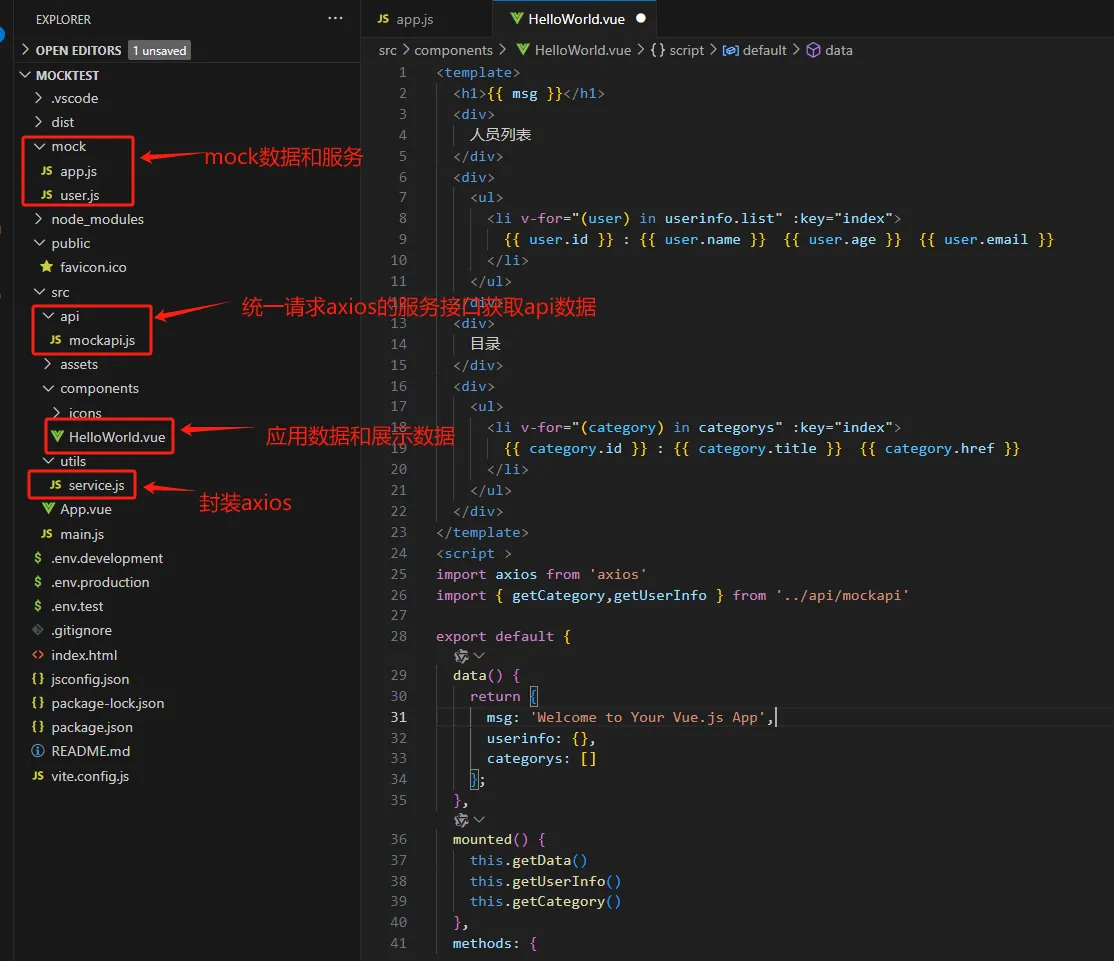
这里我们主要通过VITE_APP_API_URL变量来区分不同的环境调用不同的接口,在开发环境调用本地接口http://localhost:8000 ,在测试环境用mock接口,在生产环境调用真实接口。
3、在项目中使用环境变量
使用import.meta.env.VITE_APP_API_URL在axios请求中使用环境变量的配置来调用不同的接口。
1 | import axios from 'axios' |
查看调用的哪些环境变量,可以在在main.js打印console.log('环境变量:', import.meta.env);看一下
main.js
1 | import './assets/main.css' |
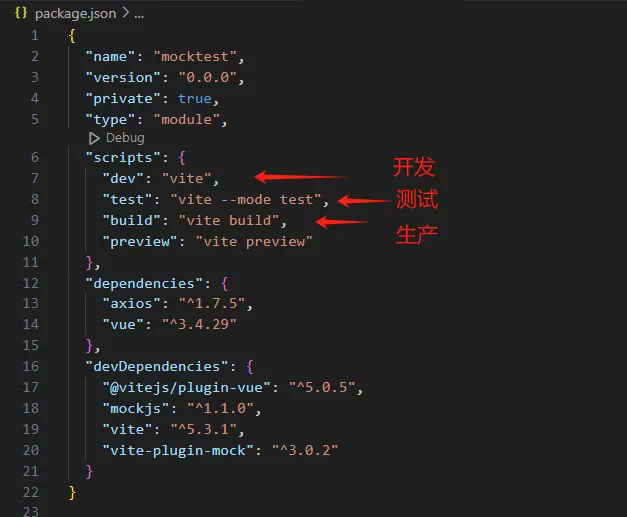
4、在package.json中定义运行项目的脚本命令
1 | { |
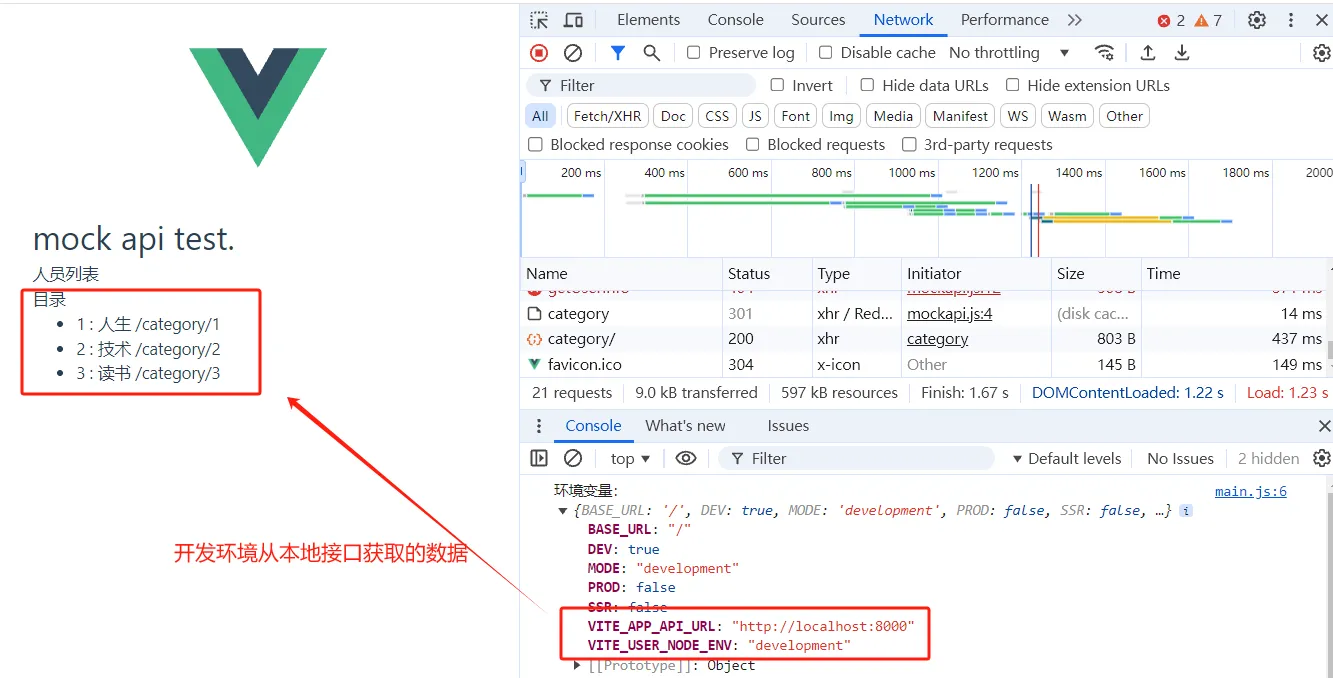
三、运行效果
开发环境运行npm run dev
测试环境运行npm run test
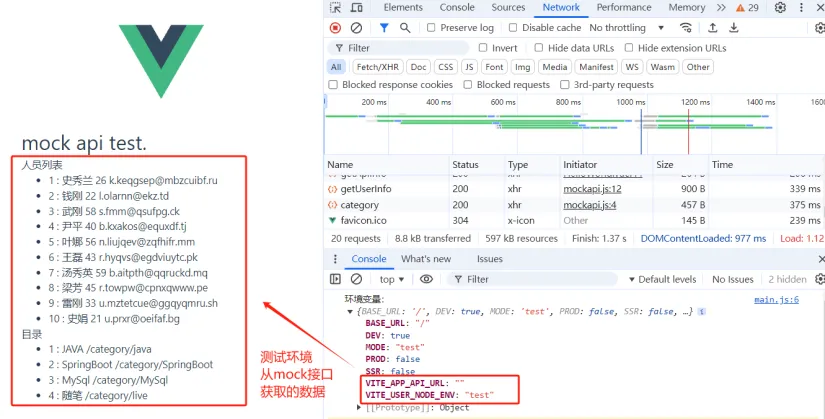
可以看出通过运行不同的命令通过环境变量区分了不同的运行环境,避免了不同环境去改代码去适配不同的环境。
博客地址:http://xiejava.ishareread.com/

关注微信公众号,一起学习、成长!