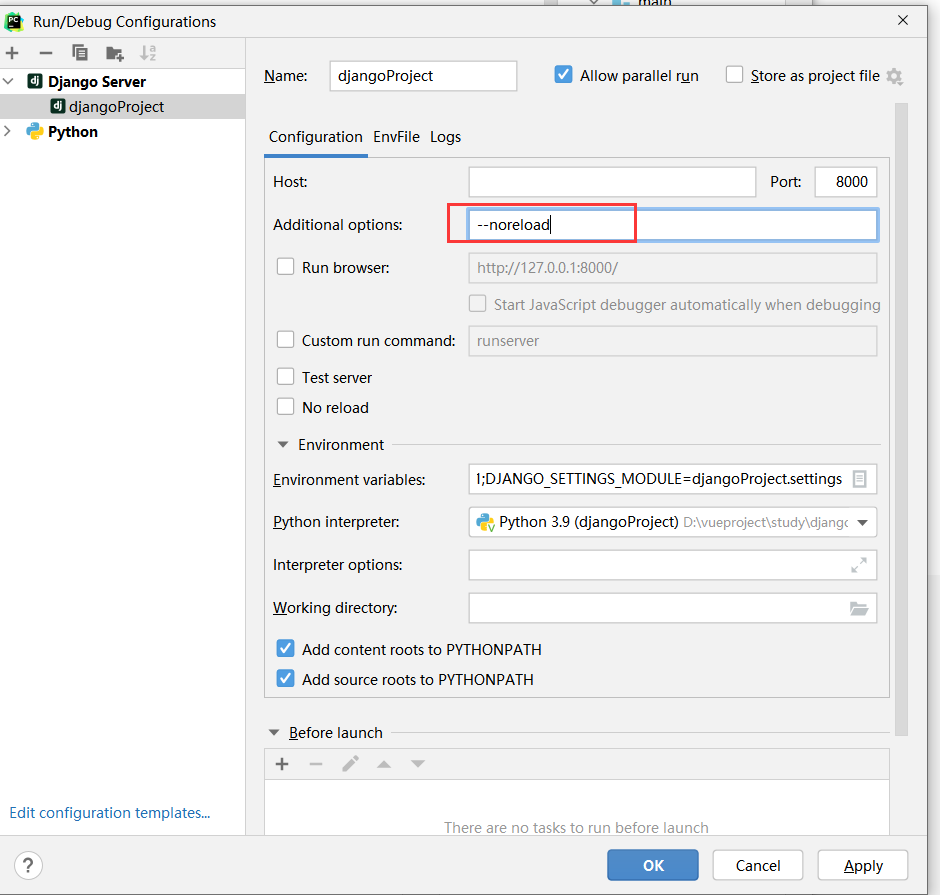
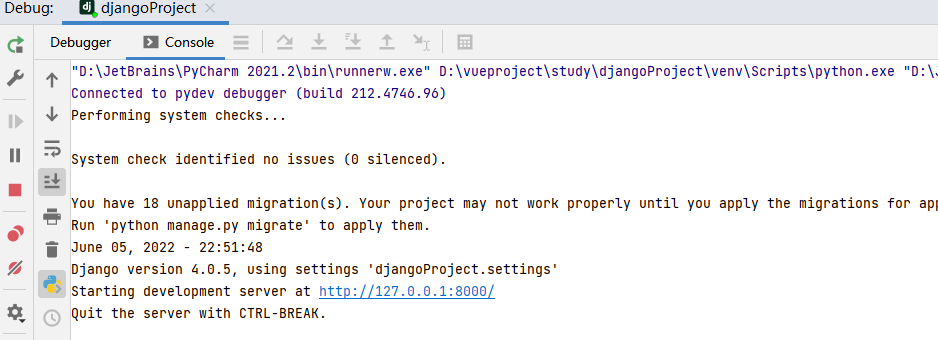
一、什么是Vue
Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化的工具链以及各种支持类库结合使用时,Vue 也完全能够为复杂的单页应用提供驱动。
二、安装
1、独立版本
直接下载并用<script>标签引入
官网下载地址:https://cn.vuejs.org/js/vue.js
2、使用CDN
和独立版本类似,与独立版本的区别就是不用下载到本地应用,直接引用CDN加速以后的地址。缺点是如果是内网封闭环境不能用,国内CDN也不稳定,国外的CDN有时无法访问。如官网的<script src="https://cdn.jsdelivr.net/npm/vue@2.6.14/dist/vue.js"></script> 就无法访问。
几个比较稳定的CDN
Staticfile CDN(国内) : https://cdn.staticfile.org/vue/2.2.2/vue.min.js
unpkg:https://unpkg.com/vue@2.6.14/dist/vue.min.js。
cdnjs : https://cdnjs.cloudflare.com/ajax/libs/vue/2.1.8/vue.min.js
3、命令行工具
Vue 提供了一个官方的 CLI,为单页面应用 (SPA) 快速搭建繁杂的脚手架。它为现代前端工作流提供了开箱即用的构建设置。只需要几分钟的时间就可以运行起来并带有热重载、保存时 lint 校验,以及生产环境可用的构建版本。更多详情可查阅 Vue CLI 的文档。
三、第一个Vue
程序员学一门新的语音或框架,都是从hello world!开始的。来看一下Vue的hello world!
将vue.min.js下载到本地,在vue.min.js的目录下新建一个hellovue.html的文件,代码如下
1 | <!DOCTYPE html> |
用浏览器打开,hello Vue! 成功的展现出来,第一个Vue就这么简单。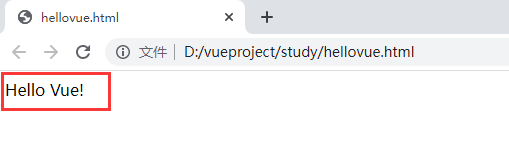
在这里我们通过<script src="vue.min.js"></script>引入了本地的vue.min.js,就可以用vue框架了。
通过<div id="app">构建了一个DOM元素div标签元素,id为app,`{{message}}` 是占位符,类似于大多数的模板语法。
1 | <div id="app"> |
在javascript代码中,定义了一个Vue对象,对象中构造了el和data两个参数。el是元素选择器,通过#app选择了id="app"的div,data用来定义数据属性,这里定义了massage:'hellow Vue!',通过`{{message}}`将数据hellow Vue显示输出。
可以用chrome浏览器的开发者工具打开控制台看到app.message的值为’hellow Vue!’。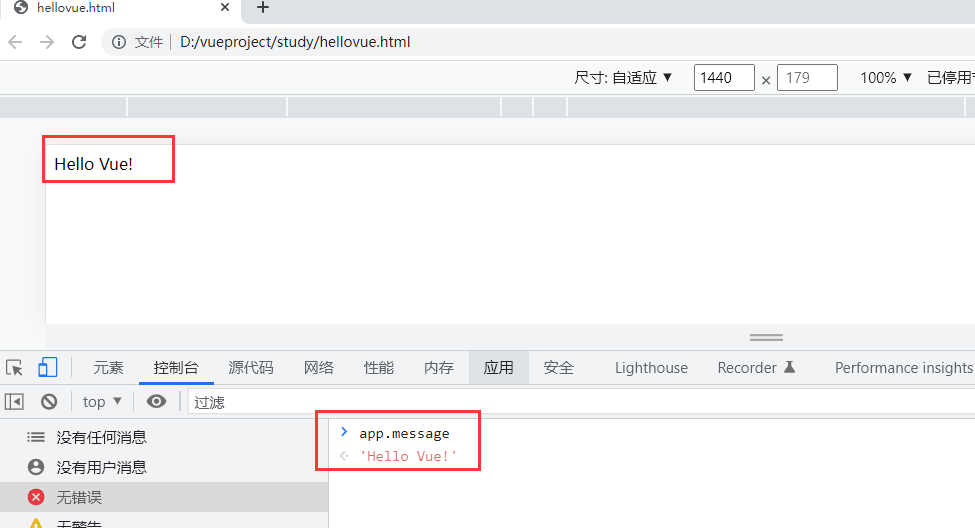
可以通过修改这个变量的值而改变显示在浏览器的值。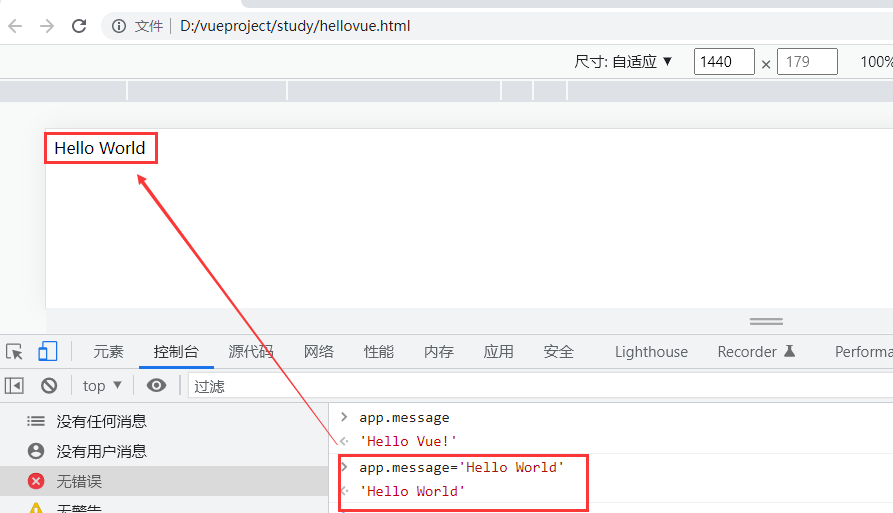
四、常用基本语法
模板语法
Vue.js 使用了基于 HTML 的模板语法,允许开发者声明式地将 DOM 绑定至底层 Vue 实例的数据。
Vue.js 的核心是一个允许你采用简洁的模板语法来声明式的将数据渲染进 DOM 的系统。
结合响应系统,在应用状态改变时, Vue 能够智能地计算出重新渲染组件的最小代价并应用到 DOM 操作上
插值文本
数据绑定最常见的形式就是使用 `{{xxx}}`(双大括号)的文本插值:
正如我们的第一的Vue通过`{{ message }}`将文本值插入到占位符进行数据绑定
1 | <div id="app"> |
绑定输出html
使用v-html 指令用于输出 html 代码:
1 | app2:v-html指令输出html代码 |
效果如下图所示: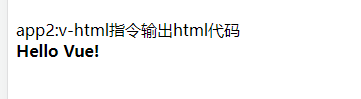
如果不用v-html插入,将<div id="app2">标签内容改成用文本插入
1 | <div id="app2"> |
显示效果如下,直接将html代码给显示出来了。
绑定属性
HTML 属性中的值应使用 v-bind 指令。
如插入绑定 a 标签的href属性
1 | app3:v-bind指令绑定属性值 |
效果如下: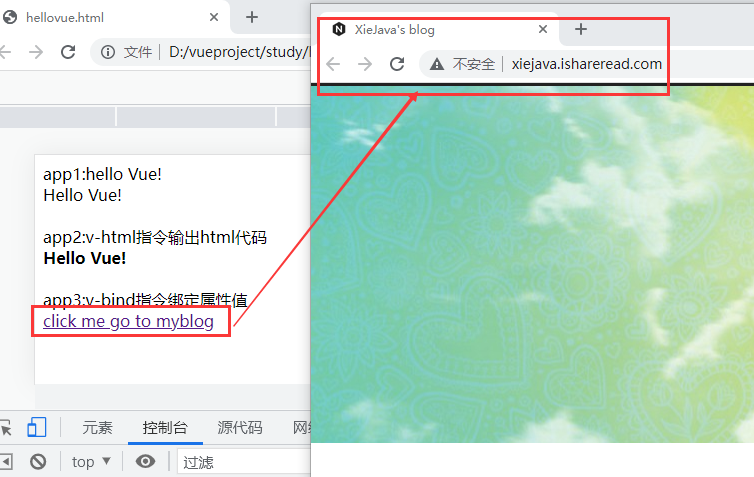
绑定样式
class 与 style 是 HTML 元素的属性,用于设置元素的样式,可以用 v-bind 来绑定设置样式属性
1 | app4:v-band:class指令绑定样式 |
定义样式
1 | <style> |
效果如下:
插值Javascript表达式
vue.js插值支持javascript表达式
1 | app5:vue.js插值的javascript表达式支持 |
效果如下:

常用语句
v-if v-else (条件语句)
条件判断使用 v-if 指令,可以用 v-else 指令给 v-if 添加一个 “else” 块:
1 | app6:v-if条件语句 |
效果如下:

for循环语句
循环使用 v-for 指令,v-for 可以绑定数据到数组来渲染一个列表
1 | <div id="app7"> |
效果如下:
v-on绑定事件
事件监听可以使用 v-on 指令进行绑定
1 | <div id="app8"> |
效果如下:

以上全部示例代码如下:
1 | <!DOCTYPE html> |
通过上面的快速入门,基本了解什么是VUE、VUE的安装及基本的使用,常用的语法。后面还要更深入的学习VUE的组件、路由、后台接口调用等。
博客地址:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!