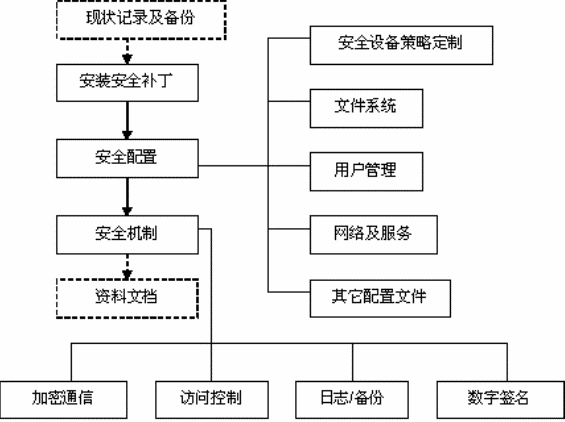
信息安全是一个动态的过程,操作系统、应用软件、中间件,还有硬件,平台的种类越来越多,技术越来越复杂,稍有不慎就会留下安全隐患和管理漏洞,依靠客户自身的IT资源无论从技术的先进性还是方案的严密性上都越来越难以应对,企业往往由于人手或技术力量的不足,无法自如的处理各种复杂的信息安全问题。针对这种情况,就需要持续对新的安全威胁、安全漏洞进行跟踪、分析和响应。
安全态势感知与监测是一种基于环境的、动态、整体地洞悉安全风险的能力,它以安全大数据为基础,从全局视角提升对安全威胁的发现识别、理解分析、响应处置能力的一种方式,最终是为了决策与行动,是安全能力的落地。
目前网络安全态势感知平台系统架构如下:
- 海量多元异构数据的汇聚融合技术:在大规模网络中,网络安全数据和日志数据由海量设备和多个应用系统中产生,且这些安全数据和日志数据缺乏统一标准与关联,在此基础上进行数据分析,无法得到全局精准的分析结果。
- 数据挖掘与智能分析技术:通过机器学习、大数据分析等技术,实现基于逻辑和知识的推理结果,从已知威胁推演未知威胁,实现对安全威胁事件的预测和判断。
- 威胁情报的共享与交换技术:通过建立威胁情报共享与交换平台,实现不同安全厂商、不同组织之间的威胁情报共享与交换,提高安全态势感知的准确性和效率。
一、安全监控
安全监控应覆盖网络、安全设备、主机、数据库、应用和中间件的安全和性能监控,具体内容如下:
| 类型 | 内容 | 监控方式 |
|---|---|---|
| 网络层 | 路由器、防火墙、IPS、WAF等 | SNMP、syslog等 |
| 主机层 | Windows2000/XP/2003、Solaris、AIX、HP-UX、Redhat Linux | SNMP、syslog、专用数据收集代理 |
| 数据库 | Oracle、MS SQL Server、Mysql、ES | SNMP、syslog、专用数据收集代理 |
| 应用中间件 | WebLogic、WebSphere、Jboss/Tomcat、Apache、IIS | SNMP、syslog、专用数据收集代理 |
一般来说将需要监控的数据统一汇聚到安全态势感知平台,通过平台的采集、汇聚、分析、展现能力,实现对网络安全的统一监控和告警通知。
二、风险感知
风险感知是指部署相应的监测措施如态势感知平台,主动发现来自系统内外部的安全风险,具体措施包括数据采集、收集汇聚、特征提取、关联分析、状态感知等。
- 数据采集
数据采集指对网络环境中各类数据进行采集,为网络异常分析、设备预测性维护等提供数据来源。 - 收集汇聚
对于数据的收集汇聚主要分为两个方面。一是对网络设备系统及应用系统所产生的安全告警数据进行汇聚,包括产品全生命周期的各类数据的同步采集、管理、存储及查询,为后续过程提供数据来源。二是对全网流量进行监听,并将监听过程中采集到的数据进行汇聚。 - 特征提取
特征提取是指对数据特征进行提取、筛选、分类、优先级排序、可读等处理,从而实现从数据到信息的转化过程,该过程主要是针对单个设备或单个网络的纵向数据分析。信息主要包括内容和情景两方面,内容指网络流量、告警日志信息等;情景指人员的操作指令、人员访问状态、登录事件、时长等。 - 关联分析
关联分析基于大数据进行横向大数据分析和多维分析,通过将运行机理、运行环境、操作内容、外部威胁情报等有机结合,利用群体经验预测单个设备的安全情况,或根据历史状况和当前状态的差异进行关联分析,进而发现网络及系统的异常状态。 - 状态感知
状态感知基于关联分析过程,实现对企业网络运行规律、异常情况、安全目标、安全态势、业务背景等的监测感知,确定安全基线,结合大数据分析等相关技术,发现潜在安全威胁、预测黑客攻击行为。
为了提高安全态势感知与监测的能力和准确性,还需要采取以下措施:
- 加强数据分析和挖掘能力:通过对海量数据进行深入分析和挖掘,发现潜在的安全威胁和漏洞。
- 建立威胁情报共享机制:通过建立威胁情报共享机制,实现不同组织之间的信息共享和协同作战。
- 加强技术创新和研发:通过加强技术创新和研发,不断推出新的安全防护措施和技术手段,提高安全防护能力。
- 加强人员培训和管理:通过加强人员培训和管理,提高人员的安全意识和技能水平,减少人为因素对网络安全的影响。
博客地址:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!